

python + tensorflow搭建通用证码识别系统教程(windows篇)
2021-06-19 admin python 1385
由于业务中需要使用验证码识别,如果使用腾讯或百度的API接口,数量大费用惊人。对于普通的字母数字混合的验证码,我们可以使用python+tensorflow来搭建本地识别服务器,速度快又节省开支。
整体来说,搭建这个系统需要了解的知识还是比较多的,调用的组件多,版本的统一等容易出错,需要根据错误提示来一一解决。为方便以后搭建,在此记录一下。
知识储备:python、Django、tensorflow,以及传统的nginx等。windows平台的搭建过程如下:
一、为了测试方便,我们使用了vmware15.5来安装windows10系统
vmware15.5下载:
链接:https://pan.baidu.com/s/1E0NZg-vVQqqUA4q33qJQvQ
提取码:3k6c
复制这段内容后打开百度网盘手机App,操作更方便哦--来自百度网盘超级会员V4的分享windows10 20h2最新版20210619:
链接:https://pan.baidu.com/s/1tIr0kWWqXeGZIfg03dAsQA
提取码:3h3t
复制这段内容后打开百度网盘手机App,操作更方便哦--来自百度网盘超级会员V4的分享二、开始安装python-3.7.7rc1-amd64
下载地址:
链接:https://pan.baidu.com/s/15WHwmtkOQw_NRCg6JhLpeg
提取码:dusv
复制这段内容后打开百度网盘手机App,操作更方便哦--来自百度网盘超级会员V4的分享注意,如果不是虚拟机安装,尽量不要安装在C盘,因为后面的组件空间占用很大,容易出现空间不足的情况。
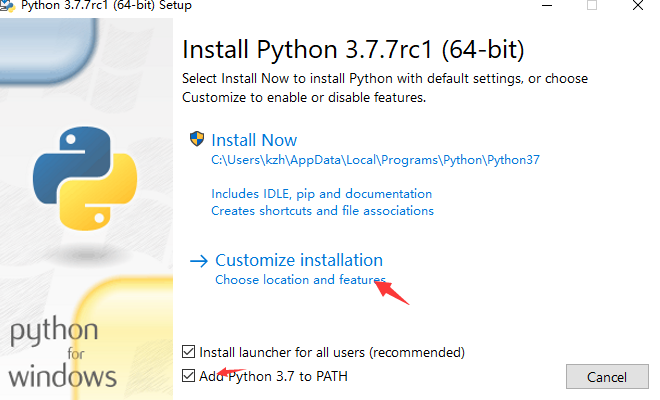
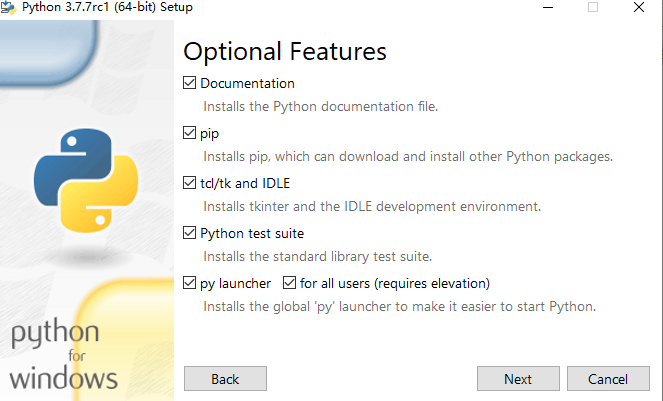
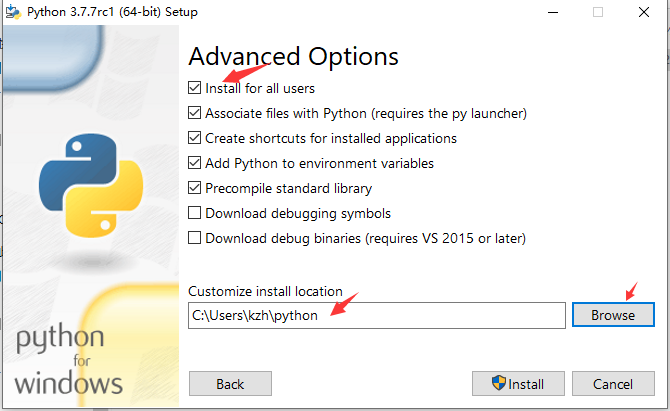
注意上面的标注,安装完后,点这:
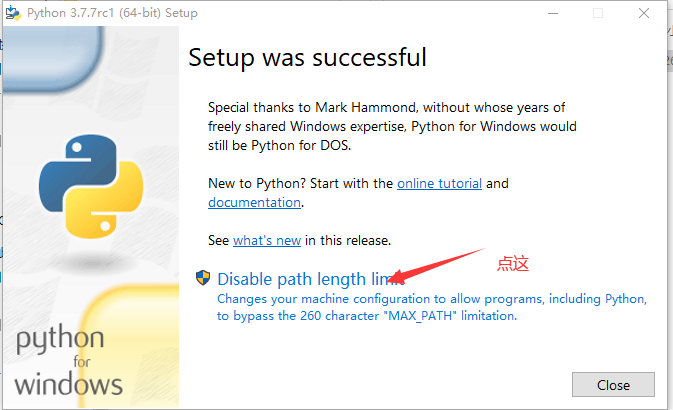
python安装完毕
三、配置安装识别组件
这个部分是最复杂的,容易报错,需要注意根据错误,缺少什么就安装什么。
为了操作方便,在C:\Users\kzh\目录下新建一个ocr目录,发送到桌面快捷方式。在目录下新建一个requirements.txt文件,内容如下:
absl-py==0.9.0
astunparse==1.6.3
cachetools==4.1.1
certifi==2020.6.20
chardet==3.0.4
gast==0.3.3
gevent==20.6.2
gevent-websocket==0.10.1
google-auth==1.20.0
google-auth-oauthlib==0.4.1
google-pasta==0.2.0
greenlet==0.4.16
grpcio==1.31.0
gunicorn==20.0.4
h5py>1.10.0
idna==2.10
importlib-metadata==1.7.0
Keras-Preprocessing>1.0
Markdown==3.2.2
numpy==1.19.0
oauthlib==3.1.0
opencv-python==4.3.0.36
opt-einsum>1.3.0
Pillow==7.2.0
protobuf==3.12.4
pyasn1==0.4.8
pyasn1-modules==0.2.8
PyYAML==5.3.1
requests==2.24.0
requests-oauthlib==1.3.0
rsa==4.6
scipy>1.6.1
six==1.15.0
tensorboard==2.3.0
tensorboard-plugin-wit==1.7.0
tensorflow==2.3.0
tensorflow-estimator==2.3.0
termcolor==1.1.0
urllib3==1.25.10
Werkzeug==1.0.1
wrapt==1.12.1
zipp==3.1.0
zope.event==4.4
zope.interface==5.1.0
Django==3.1运行cmd命令行,进入到刚才的ocr目录,执行命令安装:
pip install -r requirements.txt发现报错:

原来是万恶的windows将txt文件自动添加了txt结尾了,修改一下文件名,顺便也升级一下pip:
python -m pip install --upgrade pip然后再执行刚才的命令安装,过程要很久,下载文件很大很漫长,要耐心等待,特别是移动宽带的用户,最好用电信,否则有些包无法下载:
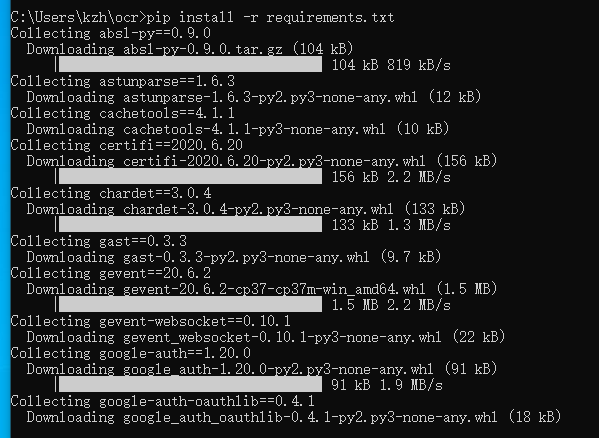
安装完成后,发现有报错:
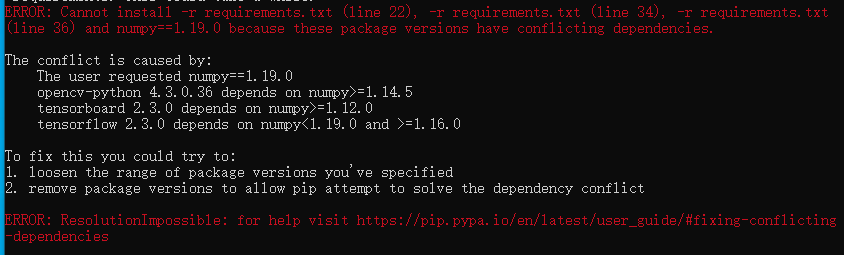
暂时不理会,先测试再说。将muggle_ocr的压缩包,解压到python3.7安装目录下的lib目录
在C:\Users\kzh\ocr目录下创建一个ocr.py文件,内容如下:
import time
import base64
# 1. 导入包
import muggle_ocr
"""
使用预置模型,预置模型包含了[ModelType.OCR, ModelType.Captcha] 两种
其中 ModelType.OCR 用于识别普通印刷文本, ModelType.Captcha 用于识别4-6位简单英数验证码
"""
start = time.perf_counter()
# 打开验证码图片,将文件数据作为字符串返回
base64img = "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAAeAEADASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD3+mRK6RhZH3sOrYxn8KwvF7yQ6VBPDNNFIt3AoMUrJkNIoIODyMHvWsmoW0moyWCmQ3EahnHlPtAPT5sbfwzWvsn7NTWu/wCFv8yeZXsWWdUxuYDJwMnqabufztuz5Nud+e/piuc+x22keL45BbQrBqCbVOwfu5V549Mj8zTmtRqmrT3VnPDbTxyCHzRGjSbFBDsu4HksQuT2Wso6uxtyLvodAoV5jIshOBsKhvlB+nrUlc5pVxctr+paTLcm7toY45RcBQjq7E5RigAJ4z0FV7m4bwpqMspcS2F3mRlY4McuOvA6Nj061c4ODsxTg4uzOol8zyz5W3f239KfWBo4MDS6hqamG9vGz84+VE/hQN0HHY4Oa1wyReetum+UMGZM4yT7moIMTxqksuhpFBFO8rXMLDyYWlKhXBJwAegGeabor3en6le6POt1KjsZ7e/a3bDbuSrtjG4fqMDjGK6Wormf7NbtLt3bccZx3xXSsRaj7JrTX79P8iHD3uYpaxpj6npfkJKEuY2WSKYjG2Reh/n+dR3yW+n6ZbWsljLd2pPlSBIjIyDa3zlQCTyMcf3s1pPMqTRxEHdJnGOnFLIsjLiNwhzyduTj29/z+lc8bJ3ZqpdHscnollNa+IJX0e2nt9H+z/NDco0KNKWyNikZGBnJxz09xoeI4mvNLMPkhJzJHy7AAqGBOHOB2PHB46Vry7LW0kZnlYfxNuy2Txken4cVLsIh2K53BcBzyc+vvVVJ87uOc+d3CKJIYxHGMKOgzSpGkSBI0VFHRVGAKqx2AgAMErxNjkL9xjxyV6Dp2xVmPzNv70JuBxlScEevt9OfrUEH/9k=="
image = base64.b64decode(base64img)
# 2. 初始化;model_type可选:[ModelType.OCR,ModelType.Captcha],ModelType.Captcha可识别4-6位验证码
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
# 3. 调用预测函数
text = sdk.predict(image_bytes=image)
end = time.perf_counter()
print('识别结果:',text,'耗时 %s 秒'%(end-start))在cmd里,输入命令测试看看:
python ocr.py报错提示cv2组件没有安装:
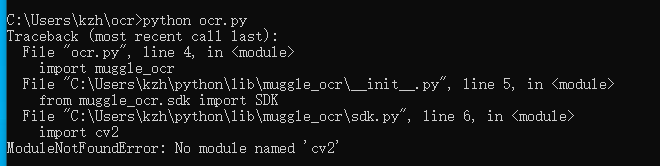
执行命令安装:
pip install opencv-python然后再测试验证码识别,如果继续报错,如:
ModuleNotFoundError: No module named 'yaml'那就再执行安装:
pip install pyyamlPTL报错:
pip install pillowModuleNotFoundError: No module named 'tensorflow'这个报错说明版本不兼容,有些系统会提示,虚拟机的windows10 20h2版本会提示,需要执行命令重新安装:
pip install tensorflow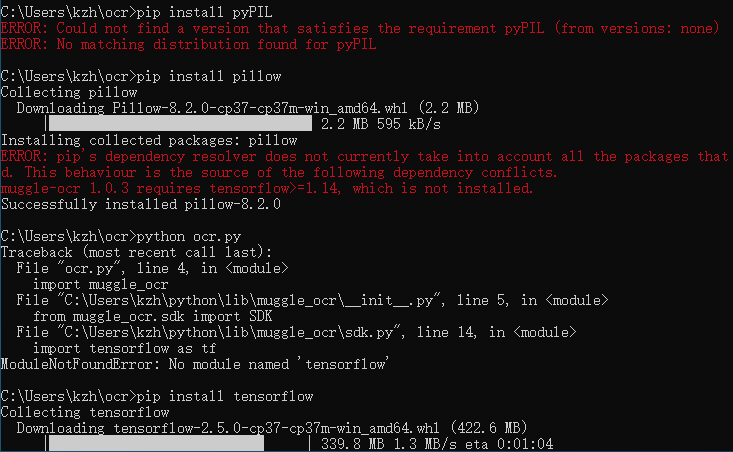
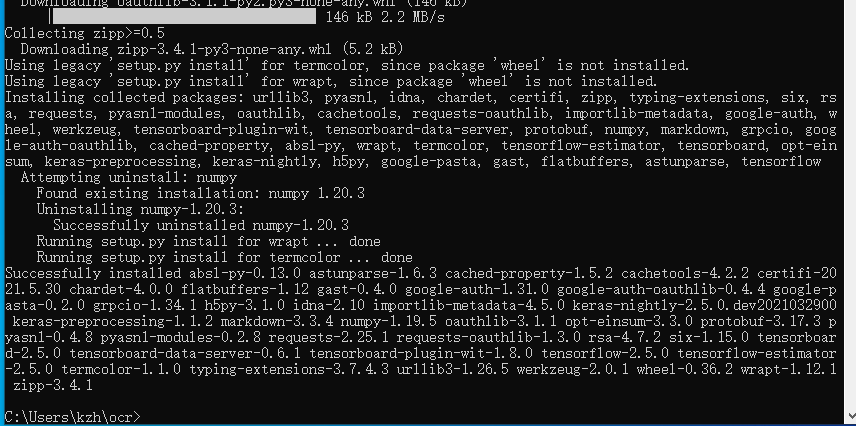
安装完成后,执行识别测试:
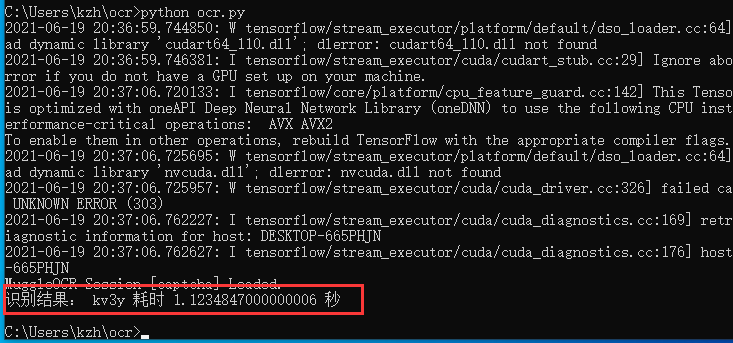
识别成功,虚拟机性能太低,识别耗时一秒多。
四、安装Django创建API调用服务
现在可以在命令行执行识别了,不过我们要实现的是,其它程序通过访问127.0.0.1?img=base64这种形式,将base64验证码图片发送过去,识别后再返回结果。
这个我们可以通过Django实现。执行命令安装:
pip install Django然后验证一下安装是否成功
>>> import django
>>> print(django.get_version())
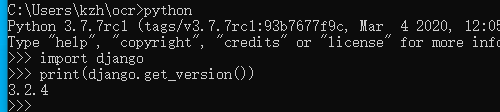
安装成功。
接下来,在ocr目录下创建一个项目,取名为webocr:
django-admin startproject webocr这行代码将会在当前目录下创建一个 webocr 目录,我们进入目录,启动一下看看:
cd webocr
python manage.py runserver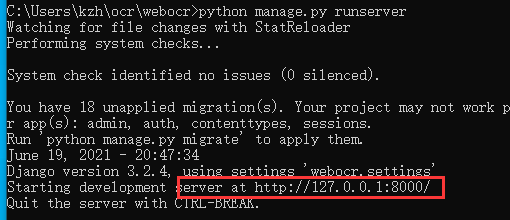
浏览器中输入127.0.0.1:8000看看:
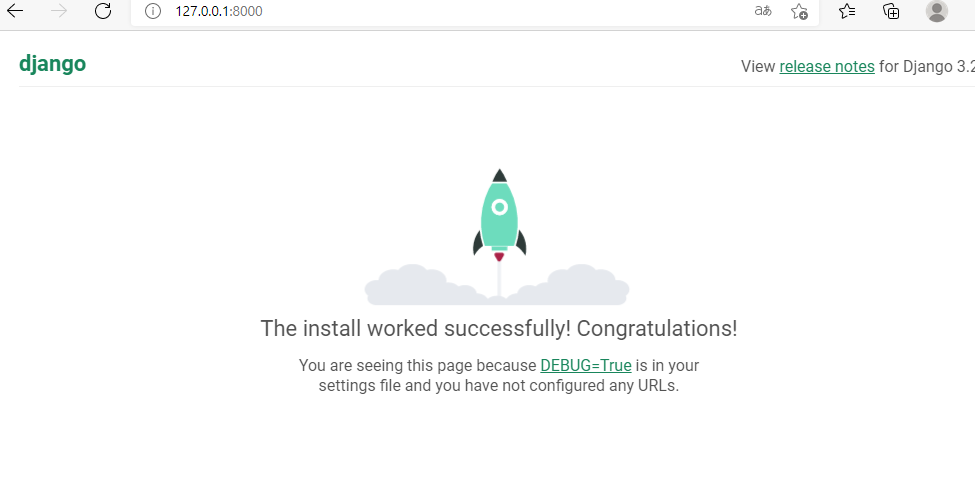
可以看到成功启动了。
五、新建一个页面通过POST方式调用
在ocr\webocr\webocr新建或修改urls.py文件:
from django.contrib import admin
from django.urls import path
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path('ocr/', views.ocr),
]新建views.py文件:
from django.shortcuts import render,HttpResponse
from django.views.decorators.csrf import csrf_exempt
import time
import base64
# 1. 导入ocr识别包
import muggle_ocr
"""
使用预置模型,预置模型包含了[ModelType.OCR, ModelType.Captcha] 两种
其中 ModelType.OCR 用于识别普通印刷文本, ModelType.Captcha 用于识别4-6位简单英数验证码
"""
@csrf_exempt
def ocr(request):
img = request.POST.get("img")
if img != "":
#图片base64经过post传输后+会变成空格,这里要替换回来
img = img.replace(" ", "+")
image = base64.b64decode(img)
# 2. 初始化;model_type可选:[ModelType.OCR,ModelType.Captcha],ModelType.Captcha可识别4-6位验证码
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
# 3. 调用预测函数
text = sdk.predict(image_bytes=image)
return HttpResponse(text)
else:
return HttpResponse("图片为空")然后通过post方式调用,为了测试方便,可将上面的POST改为GET,直接在网址中添加img参数,我这就用C#或易语言等创建的exe应用来测试了:
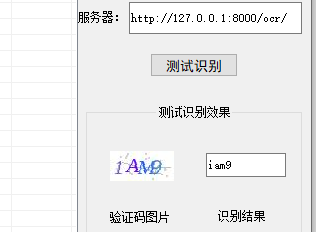
可以发现,识别成功率还是很高的。如果要外网使用,使用nginx即可。当然,如果不想麻烦,也可用外网IP直接访问的。
需要更改启动django的命令为
python manage.py runserver 0.0.0.0:8000访问的时候需要指明是http访问,格式如下:
http://192.168.75.129:8000
windows教程到此结束。