

宝塔面板使用Python管理器制作验证码识别服务器
2020-08-06 admin python 2123
python是目前最火热的编程语言了,特别是在人工智能方面,比如OCR,非常强大。
最近因需要用于验证码识别,先试用次世代验证码识别系统,发现字符粘连的无法识别,整体识别成功率不到10%,效果不满意。
最后还是考虑使用Python,毕竟CNN(卷积神经网络)识别图形验证码是非常专业的。百度找了几天资料,发现都是偏理论的,实用性不足,基本上无法用于实战,且很多都无法跑起来。最后找到了这个:muggle-ocr 1.0.3,只需要几行代码,就能使用自带的识别库,识别大部分的验证码了。安装极其简单:
pip install muggle-ocr
使用方法也非常简单:
import time# 1. 导入包import muggle_ocr"""使用预置模型,预置模型包含了[ModelType.OCR, ModelType.Captcha] 两种其中 ModelType.OCR 用于识别普通印刷文本, ModelType.Captcha 用于识别4-6位简单英数验证码"""# 打开印刷文本图片with open(r"test1.png", "rb") as f: ocr_bytes = f.read()# 打开验证码图片with open(r"test2.jpg", "rb") as f: captcha_bytes = f.read()# 2. 初始化;model_type 可选: [ModelType.OCR, ModelType.Captcha]sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)# ModelType.Captcha 可识别光学印刷文本for i in range(5): st = time.time() # 3. 调用预测函数 text = sdk.predict(image_bytes=ocr_bytes) print(text, time.time() - st)# ModelType.Captcha 可识别4-6位验证码sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)for i in range(5): st = time.time() # 3. 调用预测函数 text = sdk.predict(image_bytes=captcha_bytes) print(text, time.time() - st)"""使用自定义模型支持基于 https://github.com/kerlomz/captcha_trainer 框架训练的模型训练完成后,进入导出编译模型的[out]路径下, 把[graph]路径下的pb模型和[model]下的yaml配置文件放到同一路径下。将 conf_path 参数指定为 yaml配置文件 的绝对或项目相对路径即可,其他步骤一致,如下示例:"""with open(r"test3.jpg", "rb") as f: b = f.read()sdk = muggle_ocr.SDK(conf_path="./ocr.yaml")text = sdk.predict(image_bytes=b)
不过,在本机上直接安装时,由于宝塔面板默认的Python版本太低,无法安装。最后使用了Python项目管理器(面板可选择安装),使用虚拟环境安装成功了。方法如下:
首先,添加一个项目,设置如下:
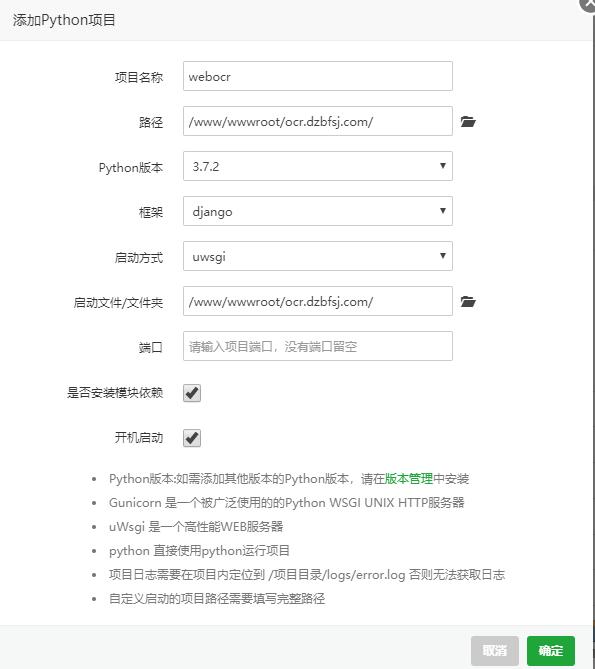
这是设置好的配置文件:
[uwsgi] master = true processes = 1 threads = 2 chdir = /www/wwwroot/ocr.dzbfsj.com wsgi-file= /www/wwwroot/ocr.dzbfsj.com/ http = 0.0.0.0:8000 logto = /www/wwwroot/ocr.dzbfsj.com/logs/error.log chmod-socket = 660 vacuum = true master = true max-requests = 1000 wsgi-file = /www/wwwroot/ocr.dzbfsj.com/ocr/ocr/wsgi.py
进入虚拟环境安装
cd /www/wwwroot/ocr.dzbfsj.com source ./webocr_venv/bin/activate pip install pybase64 pip install muggle-ocr
安装过程比较久,因为需要安装的组件比较多。
安装完后,因需要使用Django框架做WEB服务,需要检查sqlite3版本:sqlite3 -version,如果版本太低,需要到官网下载最新版编译安装。百度教程很多,注意路径就可以了。
![]() sqlite-snapshot-202007301737.tar.gz
sqlite-snapshot-202007301737.tar.gz
cd /www/server/sqlite wget xxxxxx网址 tar zxvf sqlite-snapshot-202007301737.tar.gz cd sqlite-snapshot-202007301737 ./configure --prefix=/usr/local/sqlite make && makeinstall mv /usr/bin/sqlite3 /usr/bin/sqlite3_old ln -s /usr/local/sqlite/bin/sqlite3 /usr/bin/sqlite3 source ~/.bashrc sqlite3 -version
如果正确,最后会显示最新的版本号。因时间有限,这是关键代码,完整代码我再打包上传:
from django.shortcuts import render,HttpResponse
from django.views.decorators.csrf import csrf_exempt
import time
import base64
# 1. 导入ocr识别包
import muggle_ocr
"""
使用预置模型,预置模型包含了[ModelType.OCR, ModelType.Captcha] 两种
其中 ModelType.OCR 用于识别普通印刷文本, ModelType.Captcha 用于识别4-6位简单英数验证码
"""
@csrf_exempt
def ocr(request):
if request.method == "POST":
img = request.POST.get("img")
if img != "":
#图片base64经过post传输后+会变成空格,这里要替换回来
img = img.replace(" ", "+")
image = base64.b64decode(img)
# 2. 初始化;model_type可选:[ModelType.OCR,ModelType.Captcha],ModelType.Captcha可识别4-6位验证码
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
# 3. 调用预测函数
text = sdk.predict(image_bytes=image)
return HttpResponse(text)
else:
return HttpResponse("图片为空")启动顺序,先在宝塔Python停止当前项目,再进入命令行:
cd /www/wwwroot/ocr.dzbfsj.com source ./webocr_venv/bin/activate cd ocr python manage.py runserver > nohup.log 2>&1 &
完整代码很大,将近500MB,上传到百度网盘了。
如何训练识别库呢,点击查看网址:
先下载python3.7.0 amd64版本:![]() python-3.7.0rc1-amd64.rar
python-3.7.0rc1-amd64.rar
然后,下载编译版的源码:![]() captcha_trainer-1.0.rar
captcha_trainer-1.0.rar
解压到D盘,cmd进入目录,安装依赖:
pip install -r requirements.txt